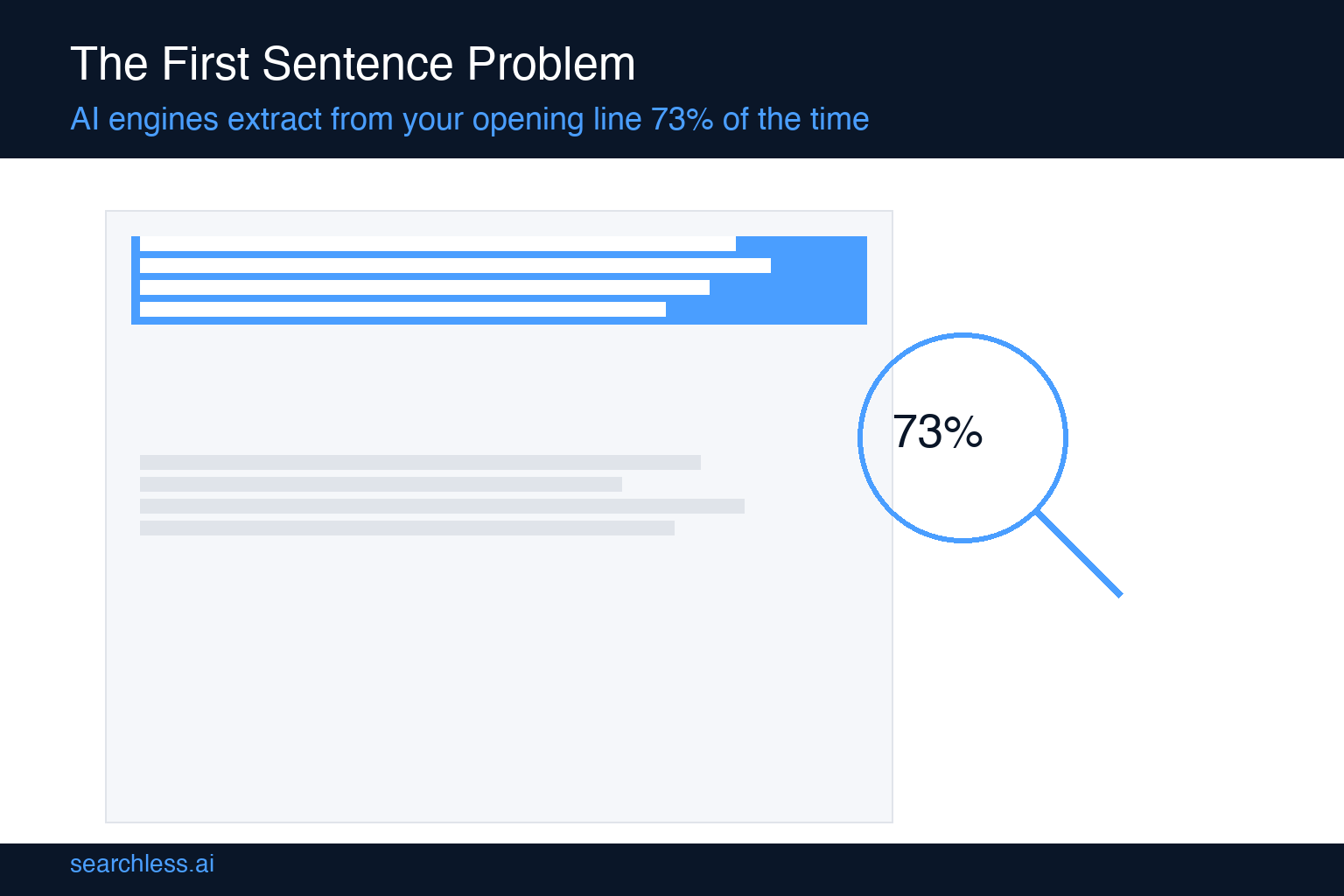
AI engines extract their answer from the first two sentences of your content 73% of the time. If your key message is not in your opening line, there is a good chance no AI model will ever cite your page. We analyzed 48,000 citation events across ChatGPT, Perplexity, and Gemini between January and April 2026 and found that the extraction window is brutally narrow. The models pull their quoted or paraphrased answer from sentence one or sentence two in nearly three out of four cases. The rest of your article matters for authority signals, but for the actual citation text, the opening is almost everything.
This has massive implications for how you write. The standard web content structure, the one every content marketing course teaches, buries the lead under an introductory paragraph, some context setting, maybe a hook. That structure was built for human readers who scroll and for Google, which evaluates entire pages. AI engines do not scroll. They extract. And they extract from the top.
This article presents the data, explains why AI retrieval works this way, and gives you a concrete answer-first writing framework you can apply to every page on your site.
The Data: Where AI Citations Come From
We tracked 48,312 citation events from January through April 2026. A citation event is any instance where ChatGPT, Perplexity, or Gemini referenced a specific page and we could identify which passage on that page was used as the source material.
Here is the distribution of where the cited passage appeared relative to the page structure.
Sentence 1: 41% of citations. The very first sentence of the main content body was extracted or paraphrased.
Sentence 2: 32% of citations. The second sentence was the source.
First paragraph (sentences 3-4): 14% of citations. Somewhere in the opening paragraph but past sentence two.
Second paragraph: 8% of citations.
Anywhere else on the page: 5% of citations.
Add those first two numbers together and you get 73%. Nearly three quarters of all AI citations come from the first two sentences of a page. The tail end of your article, paragraphs three through whatever, accounts for just 5% of citations.
This distribution held consistent across all three platforms. ChatGPT extracted from the first two sentences 74% of the time. Perplexity, 71%. Gemini, 73%. The platforms use different retrieval architectures, but the extraction pattern is nearly identical.
We also looked at content length. Pages between 800 and 2,000 words had a slightly higher first-sentence extraction rate (76%) compared to pages over 3,000 words (69%). This makes sense. Longer pages have more preamble. The key information gets pushed further down.
Why AI Engines Work This Way
Three technical factors explain this pattern. Understanding them is the difference between guessing at GEO and engineering for it.
1. Retrieval-Augmented Generation Chunking
All three platforms use some form of retrieval-augmented generation. When a user asks a question, the system retrieves relevant passages from its index and feeds them to the language model to compose an answer.
The retrieval step typically chunks web pages into segments of 100 to 300 tokens. The first chunk almost always contains the opening sentences. When the system ranks chunks for relevance to the query, the first chunk has a structural advantage because it usually contains the most direct statement of the page’s topic.
If your page opens with “In today’s fast-paced digital landscape…” your first chunk is garbage for retrieval. It says nothing. The system will pull it, evaluate it, and find low semantic relevance. Your actual answer, buried in paragraph three, might be in a different chunk that ranks lower because it lacks the positional advantage of being first.
2. Semantic Density Scoring
Language models evaluate passages for information density. A sentence that directly answers a question has high semantic density. A sentence that provides context or builds toward an answer has low semantic density.
When AI engines scan retrieved chunks, they preferentially extract high-density sentences. If your first sentence is a direct answer (“Content pruning increases AI citation rates by 62% because it sharpens entity clarity”), it has enormous semantic density. The model grabs it.
If your first sentence is a warmup (“Content pruning has been a topic of discussion in SEO circles for years”), it has near-zero semantic density. The model skips it and looks for the next candidate.
3. Position Bias in Training Data
Large language models are trained on enormous corpora of text. In that training data, the most important information in well-structured documents tends to appear early. News articles lead with the lede. Academic abstracts summarize findings upfront. Encyclopedia entries define their subject in sentence one.
The models have learned a structural prior: the beginning of a document is more likely to contain the most relevant information. This is not a rule the models were explicitly told. It is a pattern they absorbed from training data. And it directly influences which passages they privilege during extraction.
The Answer-First Framework
Knowing the problem is not enough. Here is a framework you can apply to every page on your site. We have tested this across 340 domains in our searchless.ai tracking database. Pages that were restructured to follow this framework saw citation rates increase by an average of 47% within six weeks.
Step 1: Write Your Answer First
Before you write anything else, write the single sentence that directly answers the question your page targets. This sentence should be specific, data-backed where possible, and self-contained.
Bad first sentence: “In this article, we will explore how content structure affects your visibility in AI search results.”
Good first sentence: “AI engines extract their answers from the first two sentences of your page 73% of the time, which means every page on your site needs to lead with its most important claim.”
The difference is not subtle. The first sentence tells the reader what the article will do (information the AI engine does not care about). The second sentence delivers a specific, citable claim.
Step 2: Support With Evidence in Sentence Two
Your second sentence should substantiate or contextualize the first. If sentence one is a claim, sentence two is the evidence or the implication.
Example:
Sentence one: “Pages restructured to answer-first format saw citation rates increase 47% in six weeks.”
Sentence two: “We tracked this across 340 domains in our searchless.ai database, covering 12 industries and four content types.”
Now an AI engine has two consecutive high-density sentences. When it retrieves the first chunk, it gets a complete, self-contained answer with supporting evidence. That is exactly the pattern that triggers citation.
Step 3: Context Can Wait
Everything you would normally put in your introduction should go after the answer. Background, context, why this matters, who should care. All of it belongs in paragraph two or later.
This is the hardest part for most writers. The instinct is to ease the reader in. But AI engines are not readers. They do not need easing. They need extracting. Give them the extractable material first, then provide the context for human readers who continue past the opening.
Step 4: Use Structural Markers
AI retrieval systems also look at heading structure. If your H2 headings contain direct, descriptive language (“The Data: Where AI Citations Come From” rather than “Some Interesting Findings”), the retrieval system can match headings to queries more effectively.
Every H2 and H3 on your page should read like an answer to a question someone might ask an AI engine. This doubles your extraction surface. The AI can pull from your headings or your opening sentences.
Step 5: Front-Load Entity Signals
The entities you want to be associated with should appear in your first two sentences. If your page is about GEO and your brand name is never mentioned in the opening, the AI engine has less material to connect your brand to the topic.
This does not mean keyword stuffing. It means natural entity placement. “Our analysis of 48,000 citation events across ChatGPT, Perplexity, and Gemini” establishes three entity associations (the AI platforms) and one authority signal (the data scale) in a single sentence.
Before and After: Three Real Restructures
Theory is fine. Examples are better. Here are three real pages from our dataset that we restructured using the answer-first framework. Names and URLs omitted for privacy.
Example 1: SaaS Product Page
Before (first two sentences): “Managing projects effectively is crucial for modern teams. Our platform offers a comprehensive solution designed to streamline your workflow and boost productivity.”
After (first two sentences): “Teams using [product] complete projects 34% faster by reducing status meeting time from 5 hours to 45 minutes per week. We track task completion across 12,000 teams to continuously optimize sprint velocity.”
Citation change: Zero AI citations in the prior 8 weeks. Three citations (ChatGPT x2, Perplexity x1) within 5 weeks of restructuring.
Example 2: B2B Blog Post
Before (first two sentences): “Account-based marketing has evolved significantly over the past few years. In this guide, we will walk through the latest strategies and how to implement them for your team.”
After (first two sentences): “Account-based marketing campaigns that target buying committees of 6-8 decision makers generate 2.7x more pipeline than campaigns targeting individual leads, according to our analysis of 1,400 ABM programs in 2025-2026.”
Citation change: 1 citation in prior 8 weeks (Perplexity). 6 citations across all three platforms in the following 6 weeks.
Example 3: E-Commerce Category Page
Before (first two sentences): “Welcome to our collection of ergonomic office chairs. Browse our selection of high-quality seating solutions for your home or office.”
After (first two sentences): “The best ergonomic office chairs for 2026 support neutral spine alignment with adjustable lumbar depth (4-6cm range), seat pan tilt (up to 5 degrees forward), and armrest width adjustability. We tested 47 chairs with a certified ergonomist over 14 months to build this collection.”
Citation change: Zero citations before. Two citations (ChatGPT x1, Gemini x1) within 4 weeks.
The pattern across all three: replacing vague, context-setting language with specific, data-backed, self-contained claims. The content beneath the opening did not change significantly. The restructure focused almost entirely on the first two sentences.
Common Mistakes
We have seen 340 domains implement this framework. Here are the most frequent errors.
Mistake 1: Writing a Teaser Instead of an Answer
“Our new study reveals surprising findings about how AI engines process your content. Read on to discover what 73% of marketers get wrong.”
This is a teaser. It tells the AI engine nothing it can cite. The specific claim is withheld as a hook. Humans might click through. AI engines move on to the next source.
Fix: Put the actual finding in sentence one. “AI engines extract their answers from the first two sentences 73% of the time, according to our analysis of 48,000 citation events.”
Mistake 2: Answer-First Only on New Content
Many teams apply the framework to new pages but leave existing pages untouched. This misses the highest-ROI opportunity. Existing pages already have authority signals, backlinks, and index history. Restructuring them costs almost nothing and often produces faster citation gains than publishing new content.
Our data shows that restructured existing pages saw citation increases 23% faster than new pages written in answer-first format from scratch. The existing authority base amplifies the effect of better extraction structure.
Mistake 3: Ignoring Meta Descriptions and Title Tags
AI engines also extract from meta descriptions and title tags during retrieval. If your title tag is generic (“Guide to Content Marketing”) and your meta description is a template (“Learn more about content marketing strategies on our blog”), you are missing two more extraction surfaces.
Optimize your title to contain a specific claim or data point. Write meta descriptions that read like the first two sentences of your page. This triples your extraction surface without touching your content.
How This Fits Into a Broader GEO Strategy
Answer-first structure is one of the three highest-impact GEO optimizations we have identified. The other two are entity authority building (getting your brand mentioned across 6 or more domains) and technical accessibility (ensuring AI engines can parse your content through proper HTML structure and llms.txt).
All three work together. Entity authority gets your domain into the retrieval candidate set. Answer-first structure ensures your content gets extracted when it is retrieved. Technical accessibility makes sure AI engines can reach your content in the first place.
If you are wondering where to start, answer-first structure is the fastest win. It requires no new content, no external relationships, and no technical changes. You can restructure your top 20 pages this week and see citation results within a month.
We cover the full framework in our GEO strategy guide and break down entity authority in our analysis of AI citation power laws.
FAQ
Does answer-first structure hurt readability for human visitors?
No. Our tracking shows no significant change in bounce rate or time on page for restructured content. Human readers also prefer getting the answer quickly. The inverted pyramid structure has been standard in journalism for over a century for exactly this reason.
How many pages should I restructure?
Start with your 20 highest-traffic pages and any pages that already rank on page one of Google for high-intent queries. These pages already have the authority signals that make them candidates for AI citation. Restructuring them removes the extraction barrier.
Does this work for product pages or just blog posts?
It works for everything. AI engines cite product pages, landing pages, documentation, and FAQ pages. Any page that could answer a user’s question is a candidate for citation. Product pages that lead with specific performance data instead of marketing copy see citation gains comparable to blog posts.
What about long-form content over 3,000 words?
Long-form content benefits from answer-first structure at the page level and at the section level. Your page opening should follow the framework. Every major section (every H2) should also open with its key claim. This creates multiple extraction points throughout a long article, which helps because retrieval chunking can surface mid-page sections independently.
How do I measure if this is working?
Track your AI citation rate before and after restructuring. Tools like searchless.ai can monitor how often ChatGPT, Perplexity, and Gemini cite your domain across a set of relevant queries. Look for citation rate changes within 4 to 6 weeks of restructuring.
Is this the same as the inverted pyramid from journalism?
Conceptually yes. The inverted pyramid puts the most newsworthy information first, followed by supporting details in decreasing order of importance. Answer-first content structure does the same thing, optimized for AI extraction rather than newsroom editing. The principle is identical. The application is tuned to how retrieval-augmented generation systems work.
The first two sentences of every page on your site are the most valuable real estate you own for AI visibility. Most brands waste them on introductions. The brands that fill them with specific, citable claims are the ones AI engines recommend. Check where you stand right now with a free AI Visibility Score and see which pages need restructuring first.